Better Experiments: Prioritize A/B Tests To Maximize Your Win Rate

Running an a/b test may take weeks, whereas prioritizing an a/b test idea takes minutes. You can easily maximize your win rate by prioritizing ideas before testing, while minimizing time wasted on low probability (stupid) tests. Here is how we put our best ideas forward when deciding what to test next.
Prioritization Is Only As Good As Your Assumptions
When you prioritize anything, you do so in order to maximize something specific. In the context of a/b testing prioritization might be performed to maximize more winning tests, maximize effect, lower the effort per test, or increase testing velocity, etc. I usually prioritize testing ideas with the intent to maximize the number of positive test results (assuming a long term project with potential for multiple tests and good testing sensitivity). From this perspective, my approach to prioritization surfaces testing ideas with the highest probability of winning.
Prioritization is of course only as good as the assumptions it is based on. And I make the following 3 key assumptions when ranking the ideas to assign a win probability.
- Ideas Have A Higher Win Probability, The More They Have Won In The Past
- Ideas Have A Higher Win Probability, If Backed By Customer/Qualitative Research
- Ideas Have A Higher Win Probability, The More People Believe They Will Win
Past Tests: Up To ±1 Point Per Each Similar Past Test Result
Our first and most important assumption by which we attribute points to ideas is by respecting existing evidence and tests. Respecting replicability, I feel is the most powerful element to making our test predictions (and prioritization) effective. For this reason, we always look back at past tests to predict futures ones. We assign a full point for each highly significant test (positive or negative) of an idea for which data already exists. For tests that are weaker in their significance we scale down the value (ranging from ±0.25 for an insignificant test, to ±0.5 for a suggestive tests, and a full ±1 point for a highly significant test). It's important to note that this criteria is not capped. So if we have past 100 positive tests in favor of an idea, we will prioritize this amazing idea with a value of 100.
Customer Research: 1 Point
My second assumption is to respect any qualitative customer research that exists. Therefore, we might assign a single research point if a testing idea stems from a real need/pain point grounded from: a usability study, customer survey, chat logs, customer interviews, or customer support. So far we have been only assigning a single point for an idea which has a reference to some existing piece of customer research.
Subjective Certainty: (-3 to 3 Points)
Finally, we also tap into our own subjective beliefs about whether an idea will win or not. This however is capped anywhere between -3 and 3 points. A a full ±3 point is only reserved for the highest certainty situations, whereas a 0 is reserved for no certainty (ex: I don't know if it will win or not). A ±1 is a maybe, and a ±2 is a highly likely belief. If we have multiple team members that wish to express their beliefs, we allow for that and then average the numbers (tapping into the wisdom of the crowd).
Adding It All Together For A Net Probability - An Example
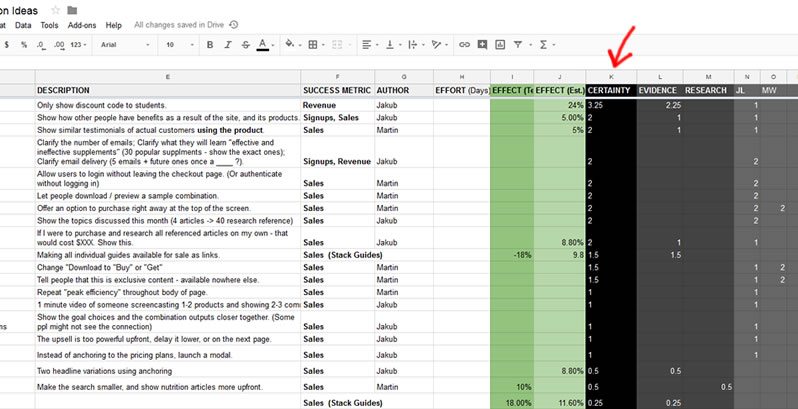
At the end of the exercise all points (from past tests, research and subjective certainty) for an idea are added into a total column (TOTAL CERTAINTY). We then sort by this column and consider to test the ideas with the highest numbers first.
View & Copy The Google Sheets Template To Use It On Your Projects
Running an a/b test may take weeks, whereas prioritizing an a/b test idea takes minutes. You can easily maximize your win rate by prioritizing ideas before testing, while minimizing time wasted on low probability (stupid) tests. Here is how we put our best ideas forward when deciding what to test next.
Prioritization Is Only As Good As Your Assumptions
When you prioritize anything, you do so in order to maximize something specific. In the context of a/b testing prioritization might be performed to maximize more winning tests, maximize effect, lower the effort per test, or increase testing velocity, etc. I usually prioritize testing ideas with the intent to maximize the number of positive test results (assuming a long term project with potential for multiple tests and good testing sensitivity). From this perspective, my approach to prioritization surfaces testing ideas with the highest probability of winning.
Prioritization is of course only as good as the assumptions it is based on. And I make the following 3 key assumptions when ranking the ideas to assign a win probability.
- Ideas Have A Higher Win Probability, The More They Have Won In The Past
- Ideas Have A Higher Win Probability, If Backed By Customer/Qualitative Research
- Ideas Have A Higher Win Probability, The More People Believe They Will Win
Past Tests: Up To ±1 Point Per Each Similar Past Test Result
Our first and most important assumption by which we attribute points to ideas is by respecting existing evidence and tests. Respecting replicability, I feel is the most powerful element to making our test predictions (and prioritization) effective. For this reason, we always look back at past tests to predict futures ones. We assign a full point for each highly significant test (positive or negative) of an idea for which data already exists. For tests that are weaker in their significance we scale down the value (ranging from ±0.25 for an insignificant test, to ±0.5 for a suggestive tests, and a full ±1 point for a highly significant test). It's important to note that this criteria is not capped. So if we have past 100 positive tests in favor of an idea, we will prioritize this amazing idea with a value of 100.
Customer Research: 1 Point
My second assumption is to respect any qualitative customer research that exists. Therefore, we might assign a single research point if a testing idea stems from a real need/pain point grounded from: a usability study, customer survey, chat logs, customer interviews, or customer support. So far we have been only assigning a single point for an idea which has a reference to some existing piece of customer research.
Subjective Certainty: (-3 to 3 Points)
Finally, we also tap into our own subjective beliefs about whether an idea will win or not. This however is capped anywhere between -3 and 3 points. A a full ±3 point is only reserved for the highest certainty situations, whereas a 0 is reserved for no certainty (ex: I don't know if it will win or not). A ±1 is a maybe, and a ±2 is a highly likely belief. If we have multiple team members that wish to express their beliefs, we allow for that and then average the numbers (tapping into the wisdom of the crowd).
Adding It All Together For A Net Probability - An Example
At the end of the exercise all points (from past tests, research and subjective certainty) for an idea are added into a total column (TOTAL CERTAINTY). We then sort by this column and consider to test the ideas with the highest numbers first.
View & Copy The Google Sheets Template To Use It On Your Projects
Posted by  Jakub Linowski on Oct 25, 2017
Jakub Linowski on Oct 25, 2017
Comments