Insignificant Significance: Why Reverb.com Rejected A Winning A/B Test
Last month we completed a simple a/b test with Reverb.com which ended with a positive 4.3% increase to sales. Taking a closer look at significance in the traditional sense, the test completed with a p-value of 0.04 (by the book significant since anything less than 0.05 is the accepted cut-off). Nevertheless, this test didn't make it through into production as it was rejected from implementation. I stand by Nicholas' (Reverb) decision 100% on this and here is our little story as to why such arbitrary significance isn't enough.
Some Background
Reverb.com is a marketplace for pre-owned electronic equipment. Customers can search for music gear and choose to purchase directly or make offers leading to possible sales. In our experiment we set out to optimize for both of these scenarios aiming to increase sales from either offers or direct purchases.
Under a coaching relationship we work together and prioritize our highest probability patterns for Reverb to execute and test. We pull positive probabilities from a highly effective assumption around repeatability - the more something works, the more it will work again. And when we were looking their product page, one such pattern surfaced and went into testing - Pattern #20: Canned Response.
The Change
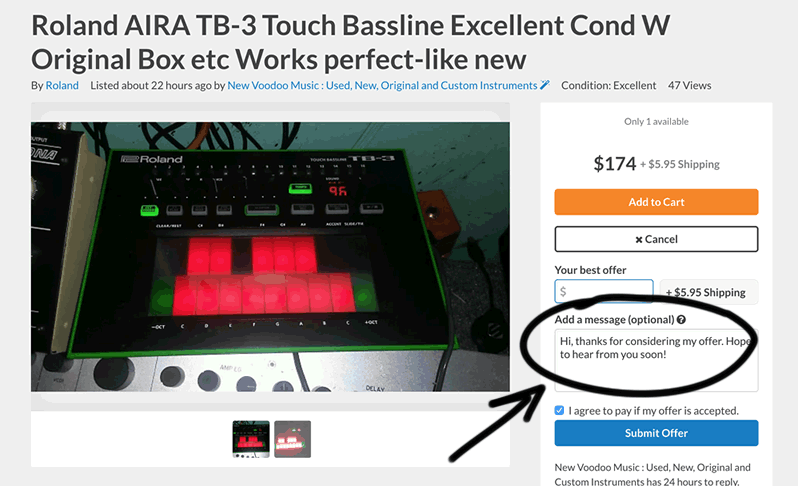
The pattern suggests to introduce a textarea field with some smart default copy which should invite more leads / form submissions. It does so using: friendly first-person language, a personalized reference to some existing choice made previously, and expectation setting on receiving an answer in return.
Note that the control already had a blank textarea, and our variation also did not include a personalized reference (ex: the name of the product that the user was looking at). These were two possible differences outside the way the pattern was defined which may or may not have weakened the effect.
The Predicted Effect
Having past test data for our pattern from Fastforward we knew that 5 similar positive tests already existed with a repeatability score of 3 (a compensation for different degrees of confidence or quality of tests). A repeatability score of 3 is actually quite high which told us that the test with the Canned Response pattern was almost certain to win - which it did as expected.

Yet, The Most Immediate Explanation Was Missing
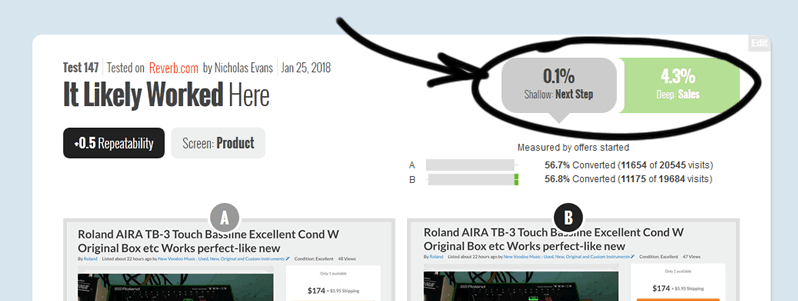
When we setup experiments it's good practice to track at least 2 metrics: a shallow and a deep metric. Our shallow metric was the most immediate step forward from the product page which we expected to increase in variation B. Imagine a series of steps from starting a negotiation (shallow measure), to a completed sale a series of steps later (deep measure). Everyone expected the Canned Response pattern to generate an increase to more negotiations being started. Yet, the impact on more negotiations was only an insignificant +0.1%.
The 0.1% increase on negotiations started wasn't matching the +4.3% increase in sales. This is a sign of trouble as our plausible explanation broke down. As much as we wanted the experiment to be implemented, the inconsistency of these two metrics was casting doubt in the whole experiment. Nicholas from Reverb called it out - rightfully so and wrote:
We are not inclined to move forward with the experiment treatment. We saw no lift in form submissions and cannot explain the small lift we saw in paid orders created from negotiations. The small lift we saw was also still fairly minor and late in the funnel. Completing the feature would involve more work, including consistency with mobile, and we don’t think it worth it at this time.
- Nicholas
Things To Consider Before Implementing A Test
This brings us to reflect and summarize what is needed before hitting the green light on rolling out a winning test. Here are some starting points:
- Confident Positive Effect
Clearly, in order to implement a test it needs to have a positive effect with enough confidence. And by confidence I mean a threshold that is set by each organization independently (ex: some organizations have to make decisions with less confidence and certainty just because they don't have enough statistical power). - Consistency Of Effect Across Multiple Metrics
As in the Reverb example above, ideally the shallow and deep metrics should be more consistent with each other. Typically as people progress through a funnel, the most immediate step should have a stronger effect (pos or negative), followed by a washed out effect further in the funnel. Of course this is the default (which was also expected above), that can have exceptions if they can be explained. - Explanation & Plausibility
A winning test needs to be explained before it can be implemented. Not having a plausible explanation could be a sign that the test is just variance high on chance and randomness - only to fade with time. - Cost-Benefit
As hinted by Nicholas, implementing a test (think translation of copy into multiple languages across devices with additional QA) can have additional costs. Hence the effect needs to be high enough for the return on investment to be more than the cost of rolling it out.
Last month we completed a simple a/b test with Reverb.com which ended with a positive 4.3% increase to sales. Taking a closer look at significance in the traditional sense, the test completed with a p-value of 0.04 (by the book significant since anything less than 0.05 is the accepted cut-off). Nevertheless, this test didn't make it through into production as it was rejected from implementation. I stand by Nicholas' (Reverb) decision 100% on this and here is our little story as to why such arbitrary significance isn't enough.
Some Background
Reverb.com is a marketplace for pre-owned electronic equipment. Customers can search for music gear and choose to purchase directly or make offers leading to possible sales. In our experiment we set out to optimize for both of these scenarios aiming to increase sales from either offers or direct purchases.
Under a coaching relationship we work together and prioritize our highest probability patterns for Reverb to execute and test. We pull positive probabilities from a highly effective assumption around repeatability - the more something works, the more it will work again. And when we were looking their product page, one such pattern surfaced and went into testing - Pattern #20: Canned Response.
The Change
The pattern suggests to introduce a textarea field with some smart default copy which should invite more leads / form submissions. It does so using: friendly first-person language, a personalized reference to some existing choice made previously, and expectation setting on receiving an answer in return.
Note that the control already had a blank textarea, and our variation also did not include a personalized reference (ex: the name of the product that the user was looking at). These were two possible differences outside the way the pattern was defined which may or may not have weakened the effect.
The Predicted Effect
Having past test data for our pattern from Fastforward we knew that 5 similar positive tests already existed with a repeatability score of 3 (a compensation for different degrees of confidence or quality of tests). A repeatability score of 3 is actually quite high which told us that the test with the Canned Response pattern was almost certain to win - which it did as expected.
Yet, The Most Immediate Explanation Was Missing
When we setup experiments it's good practice to track at least 2 metrics: a shallow and a deep metric. Our shallow metric was the most immediate step forward from the product page which we expected to increase in variation B. Imagine a series of steps from starting a negotiation (shallow measure), to a completed sale a series of steps later (deep measure). Everyone expected the Canned Response pattern to generate an increase to more negotiations being started. Yet, the impact on more negotiations was only an insignificant +0.1%.
The 0.1% increase on negotiations started wasn't matching the +4.3% increase in sales. This is a sign of trouble as our plausible explanation broke down. As much as we wanted the experiment to be implemented, the inconsistency of these two metrics was casting doubt in the whole experiment. Nicholas from Reverb called it out - rightfully so and wrote:
We are not inclined to move forward with the experiment treatment. We saw no lift in form submissions and cannot explain the small lift we saw in paid orders created from negotiations. The small lift we saw was also still fairly minor and late in the funnel. Completing the feature would involve more work, including consistency with mobile, and we don’t think it worth it at this time.
- Nicholas
Things To Consider Before Implementing A Test
This brings us to reflect and summarize what is needed before hitting the green light on rolling out a winning test. Here are some starting points:
- Confident Positive Effect
Clearly, in order to implement a test it needs to have a positive effect with enough confidence. And by confidence I mean a threshold that is set by each organization independently (ex: some organizations have to make decisions with less confidence and certainty just because they don't have enough statistical power). - Consistency Of Effect Across Multiple Metrics
As in the Reverb example above, ideally the shallow and deep metrics should be more consistent with each other. Typically as people progress through a funnel, the most immediate step should have a stronger effect (pos or negative), followed by a washed out effect further in the funnel. Of course this is the default (which was also expected above), that can have exceptions if they can be explained. - Explanation & Plausibility
A winning test needs to be explained before it can be implemented. Not having a plausible explanation could be a sign that the test is just variance high on chance and randomness - only to fade with time. - Cost-Benefit
As hinted by Nicholas, implementing a test (think translation of copy into multiple languages across devices with additional QA) can have additional costs. Hence the effect needs to be high enough for the return on investment to be more than the cost of rolling it out.
Posted by  Jakub Linowski on Feb 12, 2018
Jakub Linowski on Feb 12, 2018
Comments
Arunas 8 years ago ↑5↓0
Hi there. With this change you don't necessarily have to see the increase in form submissions. There might be multiple reasons why but my first hypothesis is that users don't see value it adding a message. They simply don't understand how can it help them to have a successful negotiation and buy the item.
However, users who were in variant of your test and who submitted the form with predefined text, made item owners more engaged. This explains why in the end you can see more successful negotiations.
So the change you introduced didn't have a direct impact on the buyers, however it definitely had positive impact on experience of item owners who received more inviting messages and therefore they felt more interested/confident in starting the conversation.
The main learning from this test is that content of conversation has significant impact on the success of negotiations between two sides and the final conversion.
Reply