Beyond Opinions About Opinions: What 70,149 Guesses Tell Us About Predicting A/B Tests
I once held the opinion that human beings should be more or less able to predict some A/B tests better than chance. It would be a sad truth if humans could not remember, nor learn anything, after running 10, 100 or 1000 A/B tests. But of course that was just a hunch – a starting point. With help from Ronny Kohavi and Deborah O'Malley, I was finally able to turn this into a measurable question: how accurate are we at predicting A/B tests? Is our predictive accuracy random, better or worse? Today, I no longer just have an opinion, but real data. Data I’d like to share with you.
Varied Opinions About Opinions
The desire to answer this question recently flared up as I spent time interacting with other industry and experimentation leaders - often on LinkedIn. Glancing through a handful of these discussions I sensed that these hunches, beliefs or opinions about opinions were quite varied. Some experimentation leaders seemed to firmly believe that we cannot predict A/B tests or felt our opinions and intuitions about websites are close to worthless.
My feeling here is that this segment of negative-biased bets often stems from agency-side leaders. I suspect some form of incentive bias might be acting out in such bets, as a higher prediction rate conflicts with the need to run (and sell) the experiment in the first place (After all, why test something, and pay for the service, if you are likely to guess the outcome?) Others, myself included, hold more neutral or slightly positive-biased beliefs about our ability to guess A/B tests. Many also feel more nuanced with some A/B tests being more easily predictable than others.
Perhaps here I should also admit that I do sell access to experimental data under GoodUI which is my own active bias. But I also do sell experiment design services just like other agencies, so there is balanced in that regard. To overcome my own bias I've purposefully stepped beyond simply my own data set and worked with two external sources.
Either way, being open to all these possibilities, let’s look at some real numbers.
The First Measure - GuessTheTest.com Data (N = 70,149)
Last month, it occurred to me that Deborah O'Malley from GuessTheTest.com might have an answer to this question. Deborah has been running a web site where various companies share A/B test outcomes. She has also been letting people guess these A/B tests in terms of very simple 2-way effect directionality: did A (control) or B (variation) do better on the primary metric or not? More importantly, she has been doing this for years and tracking the bets.
I spoke with Deborah and she was super kind to provide me with her dataset. I crunched the numbers over one weekend and ended up analyzing 70,149 A/B test guesses, along with the actual A/B test outcomes. Given the 2 possible outcomes (was A or B better) we set our randomness baseline as 50/50 (or a 0.5 probability assigned to random guessing).
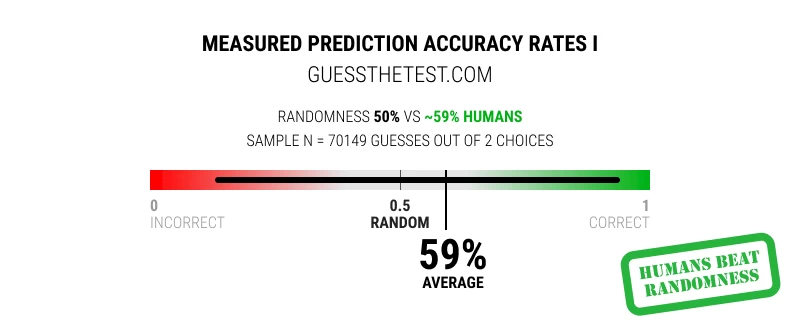
In the end, we observed that human beings were able to correctly guess these A/B test outcomes ~59% of the time, beating chance. This outcome is a very strong and optimistic signal suggesting that we might have some positive predictable accuracy about at least some experiment outcomes.
If we look at the distribution of the guesses, we can also see that some experiments are easier to predict than others. The predictive accuracy rates across each individual test ranged between ~13% and 94%.
The Second Measure - Ronny Kohavi's Class Data (N = ~700)
A single piece of evidence is good, but more evidence is even better. Last spring I enrolled in Ronny Kohavi’s 5 day live class on online experimentation - Accelerating Innovation With A/B Testing. There I also discovered that Ronny has been performing a simple exercise by showing A/B tests and asking participants to guess the outcomes. Ronny was also super nice to share his dataset with me to analyze.
In Ronny’s case however, each A/B test had 3 possible choices: A is stat-sig better, B is stat-sig better, or C no real difference (not stat-sig). Given this outcome we established our randomness baseline at a 33% accuracy rate. Analyzing the ~700 guesses we observed that participants guessed this set of A/B tests correctly ~48% of the time on average.
Once again, humans did better than chance.

The Third Measure - GoodUI Data (N = 51)
It also occurred to me that a few years ago we also did a short exercise in measuring the predictive accuracy of 51 pattern influenced experiments. We essentially tracked the outcomes of 51 A/B tests that were all predicted to be positive experiments. Given that we simply assessed the success rate as directional (was the outcome positive or negative), we assumed randomness to also deliver 50% positive and 50% negative experiments. Although the evidence here is the weakest, the outcome from this analysis was a 71% accuracy rate in obtaining positive outcomes - once again beating chance.

A Note About The Sampled A/B Test Data
One common thread between all three studies is that they contained experiments that were primarily visual, UI, copy and front-end related. For example, Ronny Kohavi's selection criteria for the test samples in his class included ones with: 1) interesting lessons to share 2) big effects, or conversely, surprisingly not stat-sig 3) debated and hard to guess, and 4) mostly visual. The GoodUI and GuessTheTest data was also primarily composed of a/b tests that were visual and copy related. Both Deborah and myself have shared somewhat popular experiments overlapping with: landing pages, ecommerce checkout flows and product pages product.
Arguably, a decent segment of these sampled experiments (not all of course) might have become somewhat common or popular knowledge. This is not necessarily a bad thing. It further reinforces that idea that some outcomes are more easily guessed than others.
Do Better Than Chance Predictions Even Matter?
I think they do, in a very optimistic sense.
Let’s first assume that all our prediction rates were random at all time. In this case, all of the following experimentation-related activities would essentially be rendered as a useless waste of time:
- Any Impact-Based Prioritization - making any impact estimations (ex: using abstracted high-low impact, or more precise estimates) wouldn’t make any sense with a random predictive accuracy.
- Compounded “Leap” Experiment Design - combining multiple changes into a single leap variation also would not make any sense. On average, multiple changes would typically counteract each other resulting in flat tests. There would be no advantage to grouping 5 changes compared to running a single change test. All would be equally random in terms of their effects.
- Decision Making - making any implementation decisions sooner outside running an experiment would always be irrational. All our decision outcomes would always cancel each other out from a mix of equally distributed good and bad decisions. We could therefore never benefit from making earlier decisions, today. We would always have to delay decision until the experiment completes.
Given that prediction rates are occasionally higher than randomness, the above activities become options that teams can exercise. And the higher our prediction rates, the more valuable the above activities.
The Fourth And Indirect Measure - Small Vs Leap Experiment Impacts
Last but not least, we can also run a comparison of experimental impact (using median effect data) between smaller and larger experiments. We have been tracking such community-contributed smaller experiments (usually with 1 to 3 changes) over at GoodUI. At the same time, we have also been tracking the impact of our own larger experiments (usually leap experiments with multiple positive probability bets in a single variation). These leap experiments were also, typically, run in the early phases of working with un-optimized websites.
As of today (as it is live data that is always being updated as new experiments come in) we can clearly see a larger impact of the bigger leap experiments (13.5%) compared against the smaller ones (4.1%).
Given that leap experiments are typically based on positive bets, it could be viewed as additional indirect evidence of the human ability to do better than chance.

Misunderstanding Prediction As Success Rates
One common source of misunderstanding is when people look at experiment success rates and believe them to be a reflection of our low ability to predict outcomes. Sometimes we might see references to the extreme low end success rates of companies like Booking and Bing with win rates of 1 out of 10. There are two problems with this assumption:
For one, predictive accuracy and experiment success rates are completely different measures. You could easily have a human being accurately predict lots of failed or flat experiments (a high accuracy of prediction with a low overall experiment success rate). There are additional factors which might be driving experimental lower success rates at highly mature companies - namely the degree of optimality and the power of regression to the mean. Essentially, optimization becomes more difficult as higher optimums are achieved.
Secondly, the often referenced 1 out of 10 success rates are also not fixed, but variable. If we look more closely, we can easily see a larger degree of variance in success rates alone. Here I’ve combined experiment success rates from Ronny Kohavi’s A/B Testing Intuition Busters paper, Georgi Georgiev’s Analytics Toolkit analysis of 1001 A/B tests, and my own GoodUI data. Hence the often referenced low success rate is just an end of the extreme range, with higher success rates being realistically common.

We Need Both Higher Prediction Rates And Experimentation
Seeing the potential of people being able to predict some experiments with a positive accuracy rate higher than randomness, is a very optimistic signal. It means that we have the capacity to learn from and remember our experiments. Striving for these higher prediction rates is very valuable and can feed directly into more effective experiments in a cyclical way.
Perhaps some might feel threatened by this finding as the higher our predictive capacity, arguably, the lower the need for the experiment in the first place. I think that the logic here is sound and rational. Of course, here we should be looking at these risks (of being wrong) and benefits (of acting sooner) in a probabilistic sense. Knowns and unknowns are not binary, they are instead probabilities, ranges and spectrums. And due to this, given any predictive accuracy rate of X% will be acted on differently by different teams. One team might consider a higher predictive accuracy as good enough to act on today, while another team might feel the need to run an experiment for greater confidence. Both are respectable decisions.
Realistically, let’s admit that we haven’t observed 100% predictive accuracy rates anywhere in any of the above data sets. There is a lot of room for being wrong. Some experiments are a lot more difficult to predict than others. Experimentation by definition shines and generates the most value when pointed at uncertainty. And that’s why we run experiments in the first place - because we don’t know or we know very little. While the unknowns are infinite, I'm glad to see that we can also learn from past experiments and predict some outcomes, at least better than chance.
Posted by  Jakub Linowski on Nov 07, 2022
Jakub Linowski on Nov 07, 2022
Comments